
我家里有超过 10 个的飞利浦 Hue 智能灯泡,我通常使用 Amazon Echo 和 iOS HomeKit 控制它们,例如说睡觉时对着 Echo 喊「Alexa, turn off bedroom.」,或者在 iPhone 上通过 Control Center 迅速开关一盏灯。在我买了一个 Raspberry Pi 架设加密 DNS 后,我就开始思考是否能在 Raspberry Pi 上跑一个程序控制 Hue 做更复杂的事情。在此之前,我先要自己搞明白 Hue 的 API 是如何工作的以及能做什么,于是我开始阅读 Hue API 文档。
Hue API 是很典型的 REST API,我们可以通过 bridge 上面的 HTTP 服务器调用 Hue API 操作这个 bridge 连接的所有灯泡。Hue API 可以操作的对象包括灯泡、房间、传感器、规则等等,不过在我们能够调用这些 API 之前,首先我们必须找到 bridge 的 IP,然后才能连上它的 HTTP 服务器。
寻找 Hue Bridge
大多数人家里的网络都是用 DHCP 动态分配 IP,因此我们不知道 Hue bridge 的 IP 是什么,就算知道了将来还可能变。我们要如何连接 bridge 呢?最简单的方法是发一个请求到这个地址:
https://www.meethue.com/api/nupnp
这是飞利浦自己的服务器,不是我们家里 bridge 的服务器。它会根据我们的公网 IP 来查询我们家是否有 bridge 通过同一个公网 IP 连接着飞利浦的服务器,如果有的话它就会返回这个(或这些)bridge 的信息,包括内网 IP。例如说:
[
{
"id": "001788fffe000999",
"internalipaddress": "10.0.0.9"
}
]
这个 JSON 里面只有一个 bridge,这也是最常见的状况。(很少人会需要在家里装超过一个 bridge。)这一个 bridge 的 IP 是 10.0.0.9,也就是 internalipaddress 属性的值。那 id 属性的值是什么呢?这是这个 bridge 的序列号,如果这个 bridge 的 IP 将来发生了变化,我们可以通过这个序列号来确认这是同一个 bridge。
在找到 bridge 的 IP 后,我们就可以连接上去了。我这里提到的只是最容易上手的 bridge 寻找办法,更复杂的方法可以看官方的 Hue Bridge Discovery Guide。
Hue Bridge 本地授权
能够连接到 bridge 的 IP 并不意味着能够操作 bridge,否则 bridge 就没有任何安全性可言了。任何新的客户端连接 bridge 之前,都需要有人去手动按一下 bridge 上面的物理按钮,然后新的客户端才能获取到授权。
首先,我们要按下 bridge 上的物理按钮,然后发送一个 POST 请求到这个地址:
http://<bridge_ip>/api
这个 POST 请求需要带上一个简单的 JSON:
{
"devicetype": "<app_name>#<device_name>"
}
这个 JSON 只有一个叫做 devicetype 的属性,用来命名这个新增的客户端,格式为应用名称加上 # 再加上设备名称。(一个应用可以安装在多台设备上,这样的命名格式要求可以帮助区分。)官方文档说这个字符串长度不能超过 40 个字符,其中应用名称不超过 19 个字符,设备名称不超过 20 个字符。实际上当前的 API 版本(1.24.0)只检查字符串长度是否超过 40,不检查应用名称和设备名称是否超过允许长度。
这个请求成功的话,返回的 JSON 会是这样子的:
[
{
"success": {
"username": "83b7780291a6ceffbe0bd049104df"
}
}
]
我们获取到了一个叫做 username 的东西,这实际上是个密钥一样的东西,因为只要掌握了它就能操作 bridge。我们需要把这个密钥保存下来,然后我们就可以进行其他任意操作了。
测试请求
拿到 username 后,我们当然要测试一下能不能用。Hue API 传输 username 这个密钥的方式很有趣,我们需要把它放在 URL 里面,例如这样子:
http://<bridge_ip>/api/<username>/config
发一个 GET 请求到这个地址,我们就能获得这个 bridge 的所有配置信息。成功获取信息意味着 username 是有效的密钥,之后我们就能用它来获取其他信息了。以下是一些可以尝试 GET 请求获取的地址:
http://<bridge_ip>/api/<username>/lights
http://<bridge_ip>/api/<username>/groups
http://<bridge_ip>/api/<username>/schedules
http://<bridge_ip>/api/<username>/scenes
http://<bridge_ip>/api/<username>/sensors
http://<bridge_ip>/api/<username>/rules
http://<bridge_ip>/api/<username>/resourcelinks
http://<bridge_ip>/api/<username>/capabilities
总结
拥有上述知识后,我们就可以进一步探索 Hue API 了。为了方便方便我自己,我写了一个叫做 Hue Explorer 的开源项目用于连接我自己的 bridge 并查看上面的信息,如果你想要看源代码的话你可以到 GitHub 上查看。我暂时只做了一部分的 JSON 可视化,例如说灯可以可视化为这样子:
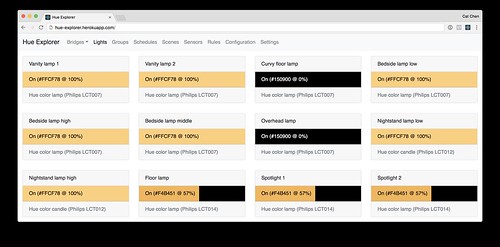
如果你想要用第三方工具发送 REST 请求,可以试一下免费的 Postman。如果你懒得下载,可以直接访问 http://<bridge_ip>/debug/clip.html,这是一个每一个 bridge 都自带的调试工具,可以用来手工编写 REST 请求。
在下一篇文章里,我会开始讲述每一个具体的 Hue API 能做什么,不想错过的话欢迎通过邮件或 RSS/Atom 订阅我的博客。