网站整体完成后,我就可以开始做各种小优化了。其中一个优化是使用 responsive image 来适应不同分辨率和不同像素密度的屏幕,用到的是 <img /> 新增的 srcset 和 sizes 属性以及新增的 <picture /> 元素。因为现在有多套新旧并存的 responsive image 方案,而且它们使用的属性存在重叠,所以要搞清楚到底这些属性如何运作,还是要动手实验。
sizes 属性
<img srcset="elva-fairy-320w.jpg 320w,
elva-fairy-480w.jpg 480w,
elva-fairy-800w.jpg 800w"
sizes="(max-width: 320px) 280px,
(max-width: 480px) 440px,
800px"
src="elva-fairy-800w.jpg" alt="Elva dressed as a fairy">
这是一段来自 MDN 的代码。虽然大家都是先写 srcset 再写 sizes,但其实更符合直觉的阅读顺序是先读 sizes。sizes 的值是一组类似 media query 的命令,它们描述了在什么情况下这个 <img /> 应该有多宽。拿上面这段代码举例:如果屏幕宽度是 320px 或以下,图片宽度为 280px;如果屏幕宽度是 480px 或以下(但 320px 以上),图片宽度为 440px;其它屏幕宽度,图片宽度默认为 800px。
这一切看起来都很简单,但这是因为我们只在讨论分辨率没在讨论像素密度。如果是 2 倍像素密度的 Retina Display,上述图片宽度计算是否保持不变?答案是跟 media query 一样保持不变。无论像素密度是多少,sizes 关注的都是 CSS 像素而不是物理像素。我觉得这个设计是合理的,因为在描述 <img /> 宽度时,我们的思维模式跟在写 CSS 时一样,所以应该使用 CSS 像素。
尽管在 MDN 的例子中 sizes 属性的取值都是固定值,但其实这里可以使用 calc() 表达式进行复杂的计算,如我的代码中就用到了 calc(100vw - 30px),意思是 100% 的 viewport 宽度减去屏幕两侧各 15px 的 margin。
srcset 属性
看完 sizes 接着看 srcset。在上面这段代码里,我们看到了一个神奇的单位叫做 w,这是指代图片文件的像素宽度。文件图片的像素宽度跟 <img /> 的 CSS 像素宽度不是 1:1 对应的吗?这需要看像素密度。如果 <img /> 的宽度是 100px,像素密度是 1 时最佳图片文件宽度是 100w;像素密度是 2 时最佳图片文件宽度是 200w;像素密度是 3 时最佳文件宽度是 300w;如此类推。
在上面这段代码中,srcset 描述了 3 个图片文件地址,它们的文件图片像素宽度分别是 320w、480w、800w。这也就是说,如果在一个 1000px 宽 1 像素密度的屏幕上,根据 sizes 这个 <img /> 的宽度应该是 800px,因此应该选择 800w 的图片文件地址;如果在一个 480px 宽 2 像素密度的屏幕上,根据 sizes 这个 <img /> 的宽度应该是 440px,但因为像素密度为 2 所以最佳图片文件宽度是 880w,由于找不到 880w 的图片文件地址所以选用略差一档的 800w 图片文件地址。
为什么 sizes 和 srcset 这两个属性要如此设计呢?因为在之前的标准(如 CSS media query)里,我们需要在代码中描述如何根据两个变量(屏幕宽度和像素密度)来选择正确的图片文件地址,这个过程超级复杂,看这篇文章就能理解为什么这样的标准不好用。为了解决这个问题,新的标准让我们把这两件事情分离开来:sizes 决定图片在 CSS 布局中的大小,但跟像素密度无关;srcset 提供文件图片像素宽度,浏览器会自行根据 sizes 的结果和像素密度作出最佳选择,我们根本不需要知道像素密度。
(如果 <img /> 在布局中的大小永恒不变,可以不设置 sizes 属性,然后在 srcset 中使用 x 单位描述像素密度而不使用 w 单位。这时候 2x、3x 可以对应不同的图片文件地址,浏览器会作出正确的选择。之所以我不选择这样做,是因为我的 <img /> 大小本身需要 responsive,所以必须用 sizes。因为 w 和 x 这两种单位不能在同一个 <img /> 上混合使用,所以我用了 w。)
src 属性
看完 sizes 和 srcset 这两个属性后,最后我们看 src 属性。这是给那些看不懂前两个属性的老浏览器看的,也就是默认的图片文件地址。
<picture /> 元素
上述 <img /> 元素属性能够实现同一张图片适应不同的屏幕尺寸和像素密度,但做不到根据屏幕尺寸现实不同的图片。我的网站首页布局本身是 responsive 的:如果屏幕宽度至少有 768px,使用左右两栏布局;否则使用一栏布局。
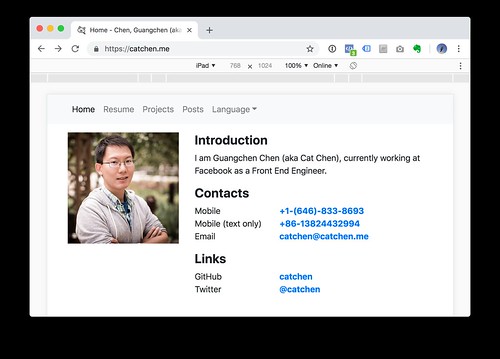
左侧栏只显示我的个人照片,所以在能够使用两栏布局时我希望显示正方形(1:1)的剪裁。同样的剪裁显示在只能显示一栏的手机屏幕上就会显得很占地方,因此我需要换个剪裁方式(3:2)减少它占用的垂直高度,把更多的首屏垂直高度留给文本信息。
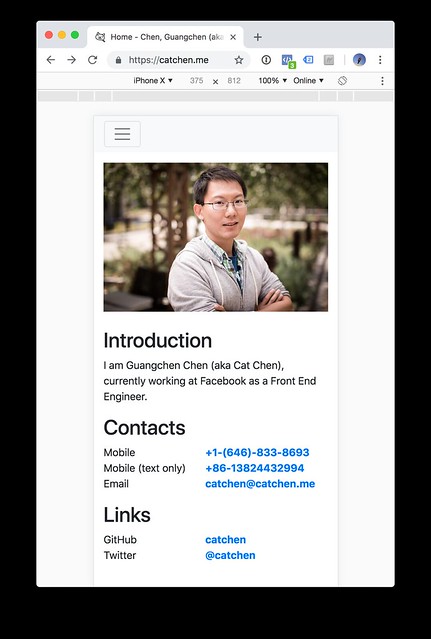
为了实现根据屏幕尺寸使用不同的剪裁,我必须引入 <picture /> 元素然后在里面放入 <source /> 和 <img />。
<picture>
<source media="(max-width: 799px)" srcset="elva-480w-close-portrait.jpg">
<source media="(min-width: 800px)" srcset="elva-800w.jpg">
<img src="elva-800w.jpg" alt="Chris standing up holding his daughter Elva">
</picture>
这也是一段来自 MDN 的代码。浏览器在碰到 <picture /> 后,就开始按顺序看里面的 <source />。每个 <source /> 元素都有 media 属性,浏览器就如同执行 media query 一样来判断这个 media 属性的值是否通过,通过了就使用这个 <source /> 来显示图片,后面的子元素都会被忽略掉。如果所有 <source /> 都无法通过 media query 检测,最后那个 <img /> 就会用来显示。(不兼容 <picture /> 和 <source /> 的老浏览器只会显示 <img />。)
由于 <source /> 支持上述 <img /> 特有的 sizes 和 srcset 属性,所以就算是放在 <source /> 中的图片也可以用上述方式支持不同的像素密度。考虑到大多数移动浏览器都会获得及时更新,能够支持 <picture /> 和 <source />,所以我选择了把正方形的剪裁当作默认剪裁放在 <img /> 里面,而针对小屏幕的剪裁放在 <source /> 里面。老旧的桌面浏览器如果打开我的网站首页,就算什么新元素和属性都不认识,至少能够根据 img.src 显示默认图片(像素密度为 1 的正方形剪裁)。
总结一下,如果需要针对不同的屏幕尺寸显示不同的图片(尤其是剪裁不一样的),必须使用 <picture /> 配合 <source /> 来选择正确的图片。一旦选定图片后,根据屏幕尺寸和像素密度设定图片尺寸只需要用到 sizes 和 srcset 属性。
我的图片优化不仅仅用到了首页的个人照片上,也用到了项目页面的截图上。在图片之后,我们还有很多其它东西可以优化的,欢迎通过邮件或 RSS/Atom 订阅我的博客,继续关注后继文章。