最近 Cloudflare 宣布使用 1.1.1.1 作为 DNS,并且强调隐私保护。由于 Cloudflare DNS 支持 DNS-over-TLS 和 DNS-over-HTTPS,这使得加密 DNS 成为了热门话题。
因为操作系统往往不支持加密 DNS,所以要使用加密 DNS 必须使用一个加密 DNS 的客户端,然后这个客户端同时作为一个明文 DNS 服务器向操作系统提供正常的 DNS 服务。我可以选择在每一台我使用的设备上安装一个加密 DNS 客户端(对于 iOS 来说则是 NetworkExtension),我也可以选择在家里假设一个加密 DNS 客户端然后把路由器 DNS 指向过去,之后家里所有设备的 DNS 都会跟着变。我选择了后者,因为这样做比较方便,也为我提供了一个折腾 Raspberry Pi 的借口——我需要把加密 DNS 客户端部署到 Raspberry Pi 上让它长期为家里的局域网提供 DNS 服务。
(为什么不用 OpenWRT 呢?因为我家里已经在用 Eero 来做路由器了,它可以通过 mesh Wi-Fi 来提供更好的覆盖。如果我要多买一个 OpenWRT 路由放在 Eero 前面,那我还不如买个 Raspberry Pi 来玩玩呢。)
Raspberry Pi
我买了这个 Raspberry Pi 套装,因为它自带盒子和电源。电源不重要,我家已经有很多 USB 电源,但是我总不能一块电路板随便一放吧,所以必须买个盒子。然后我还买了张 64GB 的 microSD。因为我所有 microSD 都是 64GB 的,所以我只买 64GB 的方便有需要时随意替换。
收到 Raspberry Pi 之后,我就按照官方 NOOBS 的指引下载和准备安装。然而 NOOBS 复制到 SD 卡后无论如何 Raspberry Pi 都无法正常启动,只亮红灯没有视频输出。搜索之后发现绿灯不亮就是没有读取 SD 卡进行启动。我开头怀疑是我下载的 NOOBS 有问题,于是换成 NOOBS Lite 和 Raspbian,但都是不行。我也怀疑过是不是下载的 zip 数据有问题,但 sha256 checksum 正确。
实在找不到问题了,我就开始搜索到底 Raspberry Pi 是如何进行引导的,发现它必须从 FAT 分区进行引导。Raspberry Pi 自己的官方文档教大家使用一个叫做 SD Association’s Formatting Tool 的软件来格式化 SD 卡,但这个软件在面对超过 32GB 的卡时就会傻傻地使用 exFAT 来进行格式化。其实使用 Mac 内置的 Disk Utility 不就好咯,就算是超过 32GB 的 SD 卡也可以选择格式化为 FAT。
把 SD 格为 FAT 后,所有问题都解决了。NOOBS 能够正常启动,接着 Raspbian 也能够顺利装上。Raspberry Pi 安装好之后我尝试启用 VNC 以便我用 Mac 远程控制,结果那上面装的 VNC 和 Mac 自带的 Screen Sharing 客户端不兼容,我只好降级到用 SSH,不过也能完成绝大多数操作了。
启用 SSH 后 Raspbian 会提醒你改默认密码,没有改的话记得改掉,否则太不安全了。因为 Raspbian 连 dig 这么基本的命令都没有,需要通过 apt-get 来安装,所以我们需要先更新一下然后把 dig 装上:
sudo apt-get update
sudo apt-get install dnsutils
DNS-over-HTTPS
我基本上就是按照 Cloudflare 的 DNS-over-HTTPS 指引 来做的。一开始我觉得 Raspbian 既然是 Debian 系的就下载了 Debian 的安装包,结果发现安装不上去。接着尝试用 Linuxbrew 来装 homebrew 的版本,结果装上后发现不能执行。看到「exec format error」并且搜索后才突然明白到,Raspberry Pi 不是基于 x86/x64 架构的,而是基于 ARM 架构的。那到底 Raspberry Pi 是 32 位还是 64 位的呢?理论上 Raspberry Pi 3 B+ 是 64 位的 CPU,但在 Raspbian 上执行 uname -a 的话会显示:
Linux raspberrypi 4.9.80-v7+ #1098 SMP Fri Mar 9 19:11:42 GMT 2018 armv7l GNU/Linux
所以其实不是 64 位的,如果要选正确的版本那必须选 32 位的 ARM。只要选择正确的版本,Cloudflared 和 Dnscrypt-Proxy 都是可以用的。我两个都装了,都能在 localhost:53 上跑起来,最后选择了 Dnscrypt-Proxy 是因为配置方便。(Dnscrypt-Proxy 有配置文件模板,改改就可以用了,不需要对着文档写一个新的。)
Dnscrypt-Proxy 的安装跟着官方指引做就可以了,选择 Linux 版本 来下载。记得下载 Linux ARM 的版本,不要用 Android 或者 ARM64 的版本。(尽管 Dnscrypt-Proxy 是可以安装在 Pi-Hole 上面的,但我不想安装 Pi-Hole 来过滤广告所以选择了非 Pi-Hole 的版本。)尽管官方指引叫你检查一下是否有别的 DNS 服务正在使用 53 端口,但新装的 Raspbian 应该是不会有任何服务占用 53 端口的所以这一步可以略过。
Dnscrypt-Proxy 下载和解压好之后就可以开始配置了。假设我们已经在 Dnscrypt-Proxy 解压好的目录里:
cp example-dnscrypt-proxy.toml dnscrypt-proxy.toml
sudo ./dnscrypt-proxy
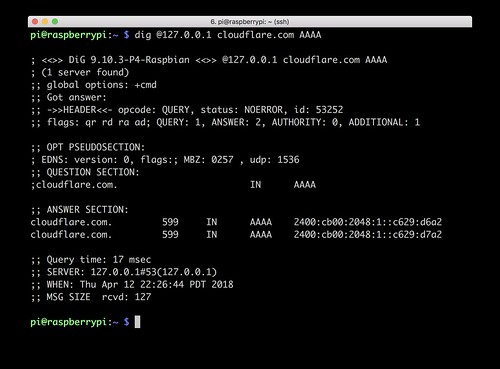
这时候 Dnscrypt-Proxy 应该能够跑起来,在 Raspberry Pi 上用 dig 验证一下就知道了:
dig +short @127.0.0.1 cloudflare.com AAAA
这个验证必须在 Raspberry Pi 上做,因为 Dnscrypt-Proxy 的默认配置只监听 localhost:53 端口,从另外一台机器连上来 53 端口是不行的。如果 Dnscrypt-Proxy 正常工作了,我们就可以开始改配置了。打开 dnscrypt-proxy.toml,然后把 server_names 和 listen_addresses 改掉。(在 SSH 上面,用 nano 或 vi 都可以编辑 dnscrypt-proxy.toml。)
首先找到 server_names,把前面注释这一行的 # 删掉,然后把后面的内容改为你想要的服务。因为 Cloudflare 和 Google 都支持 DNS-over-HTTPS,而且都是可靠的大公司,所以我在这两家之间选。因为 Google 不强调隐私,有可能记录数据,所以我只用 Cloudflare 的,按照 Cloudflare 的文档把这一行改为这样子:
server_names = ['cloudflare', 'cloudflare-ipv6']
接着找到 listen_addresses,你会发现它只监听 IPv4 和 IPv6 的 localhost,所以其他机器不能用 Raspberry Pi 来做 DNS。这时候你要想办法把 Raspberry Pi 的 IP 绑上去。我的做法是这样子的:因为我家里路由器的 IP 是 192.168.0.1,然后 DHCP 范围是 192.168.0.10–192.168.0.199,所以 192.168.0.2–192.168.0.9 是不会被动态分配出去的。我把 Raspberry Pi 的有线网 IP 写死为 192.168.0.2,然后把它加到监听地址端口列表上:
listen_addresses = ['127.0.0.1:53', '[::1]:53', '192.168.0.2:53']
搞掂之后,可以再启动一下 Dnscrypt-Proxy:
sudo ./dnscrypt-proxy
然后从另外一台机器使用 dig 测试一下:
dig +short @192.168.0.2 cloudflare.com AAAA
如果没有问题的话,就可以把 Dnscrypt-Proxy 当装系统服务启动了:
sudo ./dnscrypt-proxy -service install
sudo ./dnscrypt-proxy -service start
sudo systemctl enable dnscrypt-proxy
之后登录到路由器,把路由器的 DNS 改为 192.168.0.2 就可以了,家里所有设备的 DNS 都会经过 Raspberry Pi 上的 Dnscrypt-Proxy 走 DNS-over-HTTPS 连接 Cloudflare 服务器。尽管 Dnscrypt-Proxy 的官方指引还说要把 Linux 上的 DNS 客户端指向 localhost,但因为我暂时不在 Raspberry Pi 上做别的事情所以不在意 Raspberry Pi 本身发出的 DNS 请求是否加密。只要它作为 DNS 服务器服务好我家里的其他设备就行。
已知问题
上述做法是有一些已知问题的。首先,如果我们请求使用 SNI 的 HTTPS 服务的话,我们还是会明文传输域名的,就算 DNS 加密了还是会存在域名泄漏的情况。如果多个不同证书的 HTTPS 域名要在一个 IP 上共处,那必须使用 SNI 否则 SSL 握手时无法决定用哪个证书的密钥。因此 SNI 常见于跑在云平台上的服务,因为云平台往往在多个服务之间共享 IP,但每一个服务来自不同的客户有不同的证书。对于大型网站来说这不常见,因为无论一个大型网站旗下有多少域名,它都可以选择把所有域名放在同一个证书里面。
其次,我没有做 IPv6 的配置,只让 Dnscrypt-Proxy 绑定了一个 IPv4 地址。这时候如果 IPv6 分配了不一样的 DNS,那使用 IPv6 DNS 查询时还是会走明文的。如果你所处的网络完全不使用 IPv6,那是没问题的。我知道 Comcast 是会分配 IPv6 地址和 IPv6 DNS 的,所以如果不在路由器上设置 IPv6 DNS(或者是不能设置)的话,那 IPv6 DNS 就有可能是 Comcast 分配下来的,也就是明文 DNS。(其他 ISP 也一样。)
最后,如果你喜欢我的文章,欢迎通过邮件订阅我的博客。